Linux网络编程基础——IO模型
什么IO多路复用,同步,异步,阻塞,非阻塞,一切从最基础学习。
linux有一句著名的哲学:一切皆文件;不仅仅包括我们通常所说的文件/文件夹,其他的进程、线程、管道、套接字、代码、块设备……,一切的一切都是“文件”。文件都是以流的形势传输,又叫文件流,流其实就是文件、数据按照特点的编码格式输入输出。所以这一切的操作简称为:I/O操作,英文叫:input and output,翻译过来就是:输入和输出!
既然linux一切皆文件,那么怎么操作文件呢?这就到了第一个概念:文件描述符。
一:几个必要的概念
1:文件描述符(fd)
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
为了查看文件描述符限制,运行个命令:
$ ulimit -a #当前所有的 limit 信息
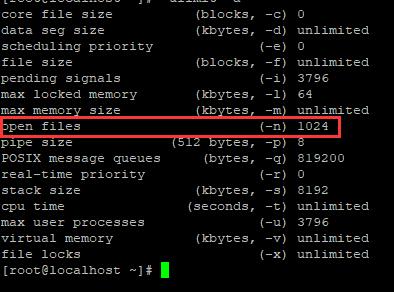
上图红线中的1024:表示文件最大句柄数,也就是单个进程最大打开的文件数默认为1024。
1024是无法做高并发的:因为linux的所有操作归根结底都是文件操作,在UNIX、Linux的系统调用中,大量的系统调用都是依赖于文件描述符。socket也不例外,所以这就是为什么我们用socket链接数TCP默认1024的原因,因为linux系统级限制,所以不管poll也好,epoll也好,什么十万、百万链接,必须先修改linux的这个限制才行。select 1024 是它自己默认的,估计也是和这个有关。
3:用户空间与内核空间:
这两个指的其实是内存的大小,计算机中的总内存=用户空间+内核空间。比如4G的内存,程序实际使用的没有4G,因为还有一部分要给操作系统内核使用,在32位的系统中,用户进程最大只能使用3G,在64位系统中最大只能使用512G。操作系统这样设计是处于安全性和稳定性。比如应用程序访问硬件,需要调用操作系统的接口来实现,这个过程就是系统调用。
但是这和我们接下来谈的网络IO模型有什么关系呢?因为网络传输也是系统调用,数据从远方发送过了,内核空间先接受数据,然后再从内核空间拷贝到用户空间……
4:进程切换:
操作系统为了控制进程的执行,必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行,这种行为被称为进程切换,任务切换或上下文切换,也就是让进程占用处理器。
上面这段话来自百度百科,不好理解,打个比喻:张三现在占用一张桌子吃饭,张三吃了两口,命令张三起来,把自己碗筷收走,李四把自己碗筷拿上来,占用饭桌继续吃……
从这里就可以看出,为什么进程切换很耗资源?老子屁股都没坐热又要让座位,牵一发动全身。
二:同步、异步、阻塞、非阻塞
1:同步(Synchronous):
同步就是程序一个个执行,执行过程中等待执行结果,执行完后再执行下一个。
2:异步( Asynchronous):
异步和同步相对,在异步调用的时候,程序不用等待,继续执行其他的,异步完成以后,通过发消息、通知、回调来通知调用者。
3:阻塞( Blocking ):
阻塞和非阻塞指的是线程的调用方式,调用结果返回之前,当前线程挂起,当前线程得到调用结果之后才会返回。这个和同步最容易混淆,同步的时候线程是激活状态的,还在占用CPU,同步的时候有可能已经执行完了,但是程序逻辑上可能没有返回而已;而阻塞的时候线程是挂起状态的。
4:非阻塞( Nonblocking):
调用不能立即得到结果之前,不会阻塞当前线程,而是立刻返回。
总结:同步和异步,关注的是消息的返回机制,是程序间的一种协作机制;而阻塞和非阻塞是进程的机制。
三:Linux5种网络IO模型
(1)阻塞I/O模型
(2)非阻塞I/O模型
(3)I/O复用模型
(4)信号驱动I/O模型
(5)异步I/O模型
(1)阻塞I/O模型(同步):
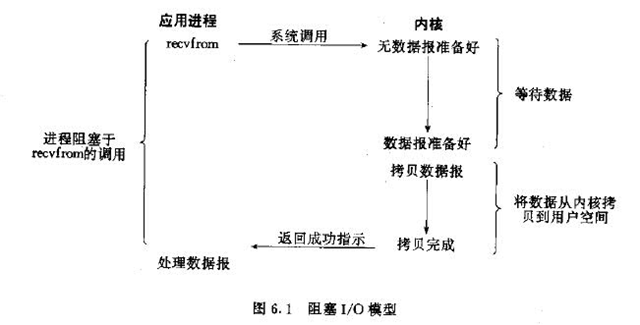 用户发出IO请求,内核检查数据是否准备好,如果没有,等待数据,用户线程处于阻塞阶段,并且交出CPU,当数据全部到位以后,内核把数据拷贝到用户线程。从图上看recvfrom后就没我CPU啥事了。
用户发出IO请求,内核检查数据是否准备好,如果没有,等待数据,用户线程处于阻塞阶段,并且交出CPU,当数据全部到位以后,内核把数据拷贝到用户线程。从图上看recvfrom后就没我CPU啥事了。
(2)非阻塞I/O模型(同步):
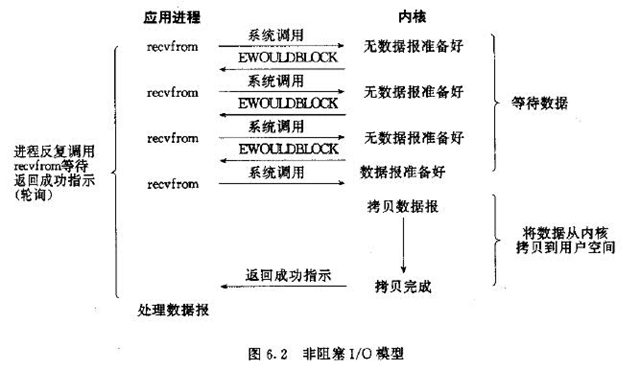 用户发出请求后,不用等待,马上得到一个返回信息,如果返回EAGAIN(EWOULDBLOCK),表示数据还没准备好,用户再次发起请求,直到数据准备好。
用户发出请求后,不用等待,马上得到一个返回信息,如果返回EAGAIN(EWOULDBLOCK),表示数据还没准备好,用户再次发起请求,直到数据准备好。
所以这个过程其实就是程序设计中的轮训,用户需要不断的询问数据是否到位,所以用户线程会一直占用CPU,这可能会占用CPU非常高。
(3)I/O多路复用模型(同步):
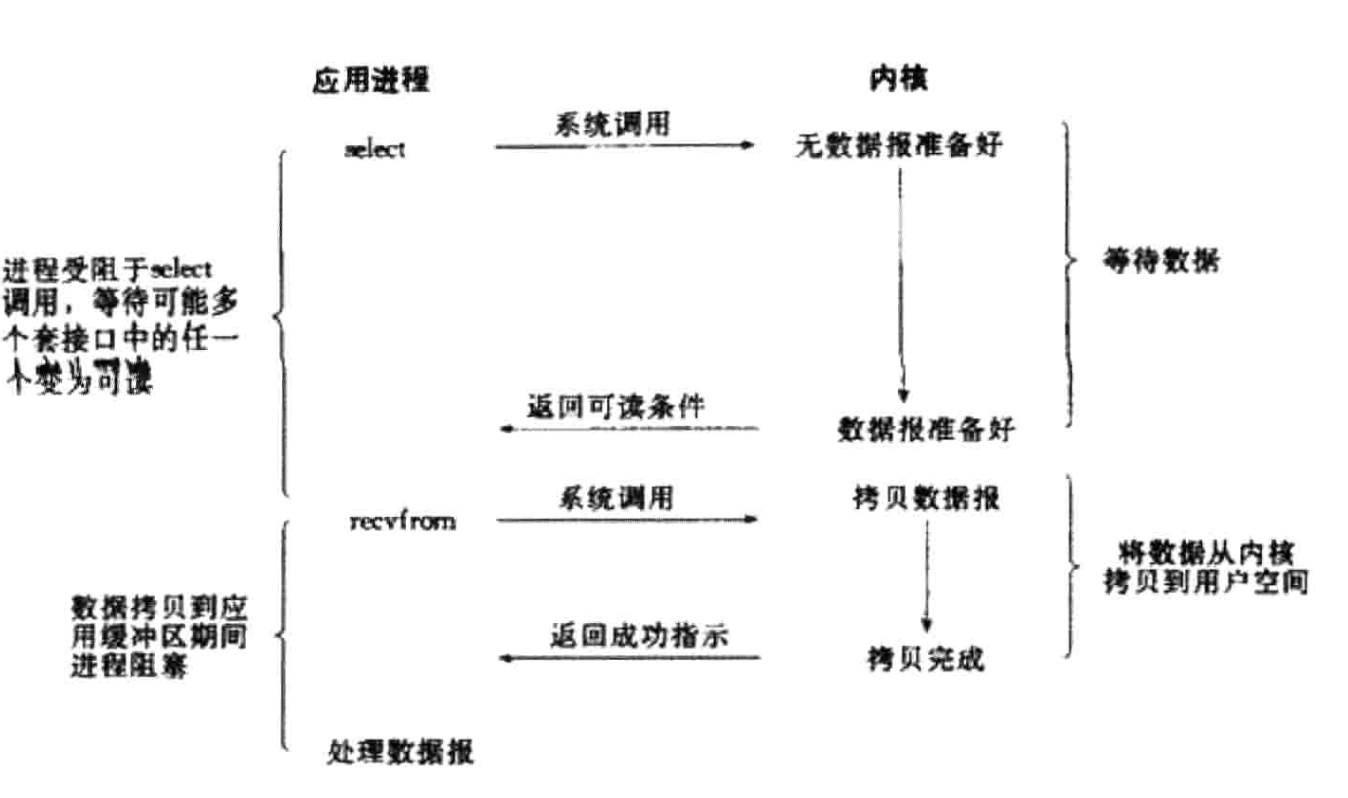 Linux有select、poll、epoll多路复用机制,进程将一个或者N个fd传递给select、poll、epoll系统调用,select函数负责等待数据是否准备就绪,所以阻塞就是在select操作的时候。这个调用是内核级别的。select对这些fd循环监听,某个fd准备就绪,就对某个fd进行处理。
Linux有select、poll、epoll多路复用机制,进程将一个或者N个fd传递给select、poll、epoll系统调用,select函数负责等待数据是否准备就绪,所以阻塞就是在select操作的时候。这个调用是内核级别的。select对这些fd循环监听,某个fd准备就绪,就对某个fd进行处理。
select/poll:是顺序扫描fd,支持的fd有限,有最大数限制,当然可以修改最大值,但是它的处理方式先创建一个事件列表,然后把这个列表发给内核,返回的时候,再去轮询检查这个列表,这样在描述符比较多的时候,效率就显得比较低下了。select:默认1024,poll默认:fd最大上限值。
epoll:基于事件驱动方式,效率更高。通过回调通知机制,减少了扫描和频繁的内存拷贝,从而显得高效,适合很多链接,但是链接并不活跃。比如几百万链接,但活跃的并不多,这种情况适合epoll。
多路复用IO依然是阻塞IO,但是一个线程管理管理多个I/O流(链接、socket),而且只有当数据准备就绪的时候才会操作,这样极大的节约了系统资源。
(4)信号驱动I/O模型(同步):
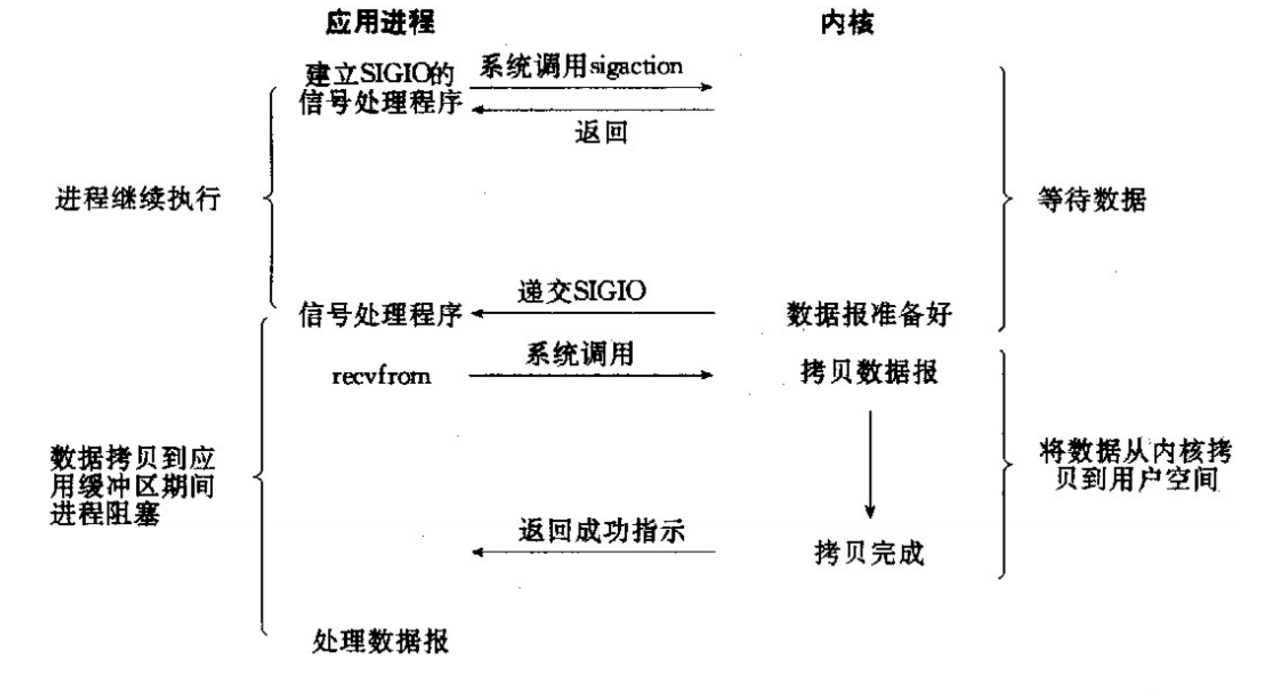 用户进程首先通过sigaction系统调用注册SIGIO的信号处理程序,然后内核立刻返回给用户SIGIO(发送信号),内核开始等待数据,等到数据准备就绪,内核再给用户进程SIGIO(发送信号),然后用户进程调用recvfrom(接受数据),内核开始拷贝数据到用户空间中,完成后在发送成功提示。
用户进程首先通过sigaction系统调用注册SIGIO的信号处理程序,然后内核立刻返回给用户SIGIO(发送信号),内核开始等待数据,等到数据准备就绪,内核再给用户进程SIGIO(发送信号),然后用户进程调用recvfrom(接受数据),内核开始拷贝数据到用户空间中,完成后在发送成功提示。
这种模型不太常用,尤其不适合TCP,因为TCP产生SIGIO频繁,链接,端口,发送,接受都会产生SIGIO,不能准确判断原因。而UDP产生SIGIO有两种情况,1:信号到达产生SIGIO,2:发送错误产生SIGIO。所以在UDP中我们接受到SIGIO,只要SIGIO没发生错误,我们就可以判断数据已经达到。
(5)异步I/O模型(异步):
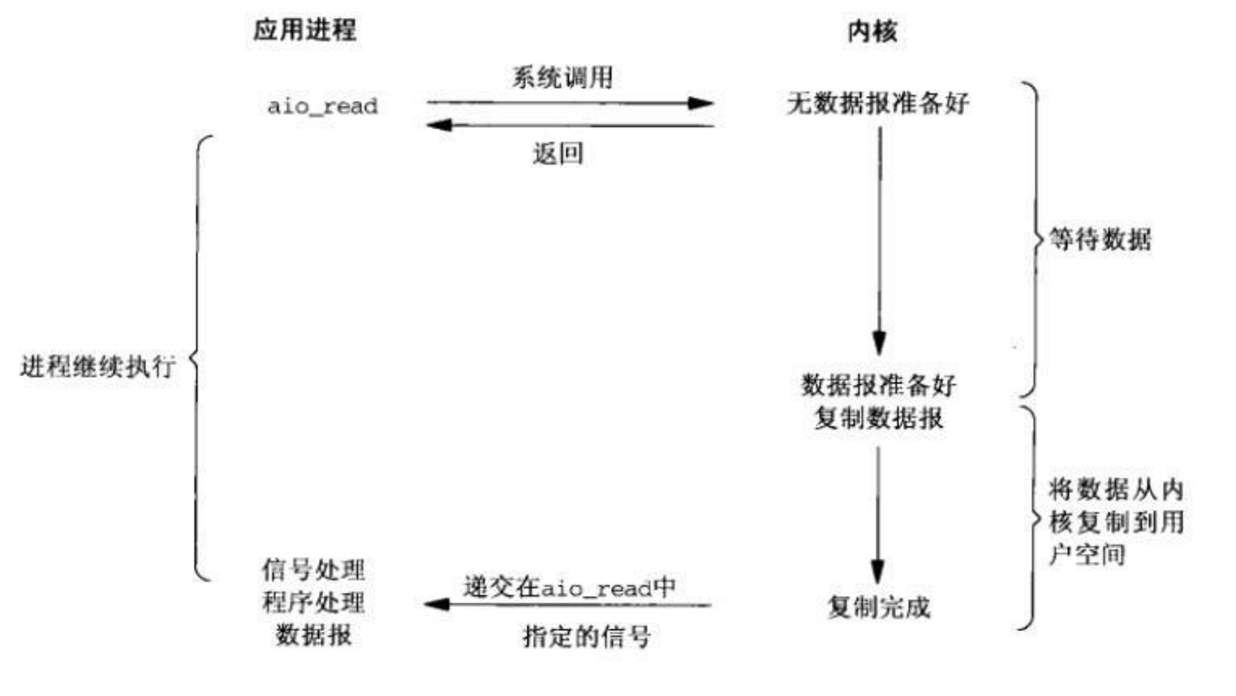 应用程序发出异步调用,不能马上得到结果,内核会干两个事情,1:释放用户线程(程序控制权),应用程序可以去干其他别的事情。2:内核开始处理数据,当数据准备就绪,再把数据从内核中拷贝到用户空间,返回异步调用时的函数处理程序。
应用程序发出异步调用,不能马上得到结果,内核会干两个事情,1:释放用户线程(程序控制权),应用程序可以去干其他别的事情。2:内核开始处理数据,当数据准备就绪,再把数据从内核中拷贝到用户空间,返回异步调用时的函数处理程序。
总结:为什么异步I/O模型才是真正的异步?而前面四种都是同步IO?因为前面四种在IO的第二步操作都会阻塞,阻塞什么?阻塞用户线程。第二步就是内核拷贝数据的过程中会有等待。只有异步I/O模型中的IO第二步,会释放用户线程,用户线程不必等待,可以去干其他的事情,这就是真正的异步。
参考资料:
《UNIX网络编程》
https://my.oschina.net/xinxingegeya/blog/3009383
https://blog.csdn.net/ZWE7616175/article/details/80591587
http://www.pianshen.com/article/8234220507/
