Mysql分区技术
一:介绍:
Mysql优化,无非两种优化,一种是大表拆小表,分库分表,另外一种就是SQL语句的优化,SQL语句的优化主要是索引优化,以及数据库结构优化。
分表:分为垂直分表和水平分表,一般以水平分表为主:
优点:真正意义上的分表,提升单个表的性能。
缺点:对逻辑不透明,代码需要改动,维护成本较大。
分区:分区技术是Mysql5.1开始提出的,类似于分表,分区是在逻辑层进行的分表技术,把一个表分成N个区块,对于应用程序而言它还是一张表。所以它对程序是透明的,逻辑代码不需要改动。
二:5种分区模式
Range(范围) – 这种模式允许DBA将数据划分不同范围。
Hash(哈希) – 这中模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区,。例如DBA可以建立一个对表主键进行分区的表。
Key(键值) – 上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
List(预定义列表) – 这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割。
Composite(复合模式) - 以上模式的组合使用(不太常用)
三:分区模式举例说明:
1:Range分区
Ranage是范围分区,既然是范围分区,那么肯定就是根据一个范围存储数据
案列:t1表保存了若干年的数据,现在这个数据表很大,打算按照Range分区处理,以提高性能。
CREATE TABLE `t1` (
`id` int(8) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (id,date),
`date` int(11) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
PARTITION BY RANGE(date)
(
PARTITION p1 VALUES LESS THAN (2008),
PARTITION p2 VALUES LESS THAN (2010),
PARTITION p3 VALUES LESS THAN (2015),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
这里把t1表分成p1,p2,p3,p4按照Range分为四个分区,分区列是date,小于2008年的数据保存在p1,>=2008,小于2010的数据保存在p2,大于等于2015的在p4分区
这里有个坑必须要注意,如果Mysql分区表中存在主键或者唯一键,那么分区列必须包含在其中,比如这里id是主键,分区的列date就必须和id弄成一个组合索引,单独给date弄一个索引都不行,没有其他办法。
新建成功后查看一下mysql存储:
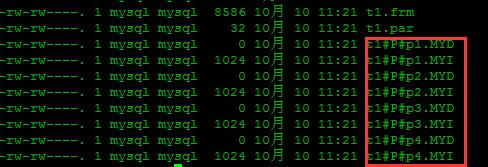 可以看到4个分区新建成功
可以看到4个分区新建成功
2:List分区
预定义列表分区
案列:t2表保存了若干年的数据,现在这个数据表很大,打算按照list分区处理,以提高性能,这种适合固定表。
CREATE TABLE `t2` (
`id` int(8) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (id,date),
`date` int(11) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
PARTITION BY LIST(date)
(
PARTITION p1 VALUES IN (2010,2011,2012),
PARTITION p2 VALUES IN (2013,2014,2015),
PARTITION p3 VALUES IN (2016,2017,2018)
);
p1分区保存了2010,2011,2012的数据,p2,p2以此类推。
3:HASH分区
HASH分区无需定义分区的条件。只需要指明分区数即可,这种一般用来,以后数据库不知道出现什么值的情况下,通过hash分布。
CREATE TABLE `t3` (
`id` int(8) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (id,date),
`date` int(11) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
PARTITION BY HASH(date)
PARTITIONS 4;
这里根据date列做哈希值,然后分配到4个区块中。
其他两个分区不常用,先不介绍,我们现在先搞点数据,实战一下。
四:模拟实战
准备:弄两个表,t1和t2,两个表500万数据。对比一下性能,根据ID哈希分区。通过存储过程插入500万数据。
1:t1表:不分区
(1):创建t1表:
CREATE TABLE `t1` (
`id` int(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`data` varchar(15) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
(2):创建存储过程,名称:load_t1
DELIMITER //
CREATE PROCEDURE load_t1()
begin
declare i int default 0;
while i <=5000000
do
insert into t1 (`data`)values(CONCAT_WS('','abc',i));
set i = i+1;
end while;
end
//
DELIMITER ;
注意红色部分,mysql默认分隔符是分号,先改为 //代替分号,然后再改回来,否则会报错。
show procedure status \G #查看存储过程是否创建成功 call load_t1 #执行存储过程执行存储过程插入数据
 执行时间2分多钟
执行时间2分多钟
再看看数据文件,不看不知道,一看吓一跳,两个字段,500万数据,数据文件是96M,索引就占了50M,所以在用索引做优化的时候,并不是索引越多越好,索引会占用大量的空间,同时维护索引成本也很高。

2:t2表:分区
(1):创建t2表
CREATE TABLE `t2` (
`id` int(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`data` varchar(15) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
PARTITION BY HASH(id)
PARTITIONS 4;
(2):创建存储过程,名称:load_t2
DELIMITER //
CREATE PROCEDURE load_t2()
begin
declare i int default 0;
while i <=5000000
do
insert into t2 (`data`)values(CONCAT_WS('','abc',i));
set i = i+1;
end while;
end
//
DELIMITER ;
执行存储过程,插入数据:
 竟然执行了3分多钟,插入比不使用分区还慢
竟然执行了3分多钟,插入比不使用分区还慢
看看数据文件:
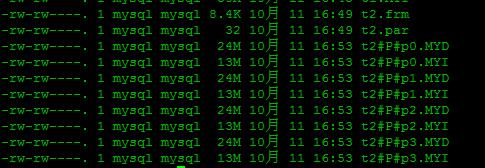 可以看到数据保存在4个分区中
可以看到数据保存在4个分区中
3:再对比一下查询,我们加入一千万数据对比一下。
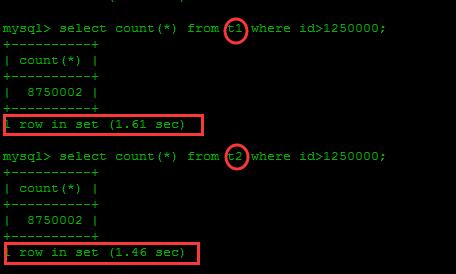 可以看到差别并不大,1000万行数据,在都添加索引的情况下,差别并不大。当然虽然有1000W数据,但数据流并不大,不过可以肯定的是分区消耗服务器资源肯定要少很多。
可以看到差别并不大,1000万行数据,在都添加索引的情况下,差别并不大。当然虽然有1000W数据,但数据流并不大,不过可以肯定的是分区消耗服务器资源肯定要少很多。
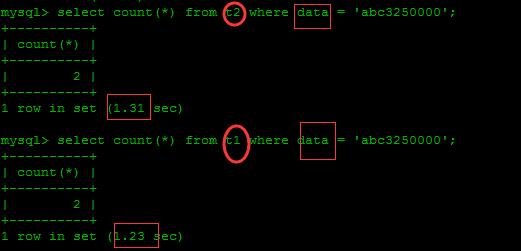 data字段没有加索引,未分区的还快一点,那是因为这里分区键是id,它是根据id找分区的,如果根据其他字段搜索,则会搜索整个分区。
data字段没有加索引,未分区的还快一点,那是因为这里分区键是id,它是根据id找分区的,如果根据其他字段搜索,则会搜索整个分区。
五:关Innodb
如果Innodb表添加分区没有成功,需要修改配置,然后重启Mysql
[mysqld] innodb_file_per_table=1因为Innodb是共享表空间,Mysql会把InnoDB引擎的表数据存储在一个共享空间中:ibdata1,增删查改都不会伸缩,所以更不能分区;MyISAM就是单独表空间。这个配置就是把Innodb改为单独表空间。
