sphinx+mysql+php构建千万级搜索引擎
一:介绍
Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。
Sphinx 单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
二:安装sphinx
1:下载地址:http://sphinxsearch.com/ 我这里下载Sphinx 3.0.3 released
2:安装编译,2.X版本需要编译,3.0及以上版本解压直接用即可
$ wget http://sphinxsearch.com/files/sphinx-3.0.3-facc3fb-linux-amd64.tar.gz #下载 $ tar -xvf sphinx-3.0.3-facc3fb-linux-amd64.tar.gz #解压 $ cp sphinx-3.0.3/etc/sphinx.conf.dist sphinx-3.0.3/etc/sphinx.conf #修改配置文件后缀为.conf
sphinx使用步骤:
1、mysql先建立数据
2、建立Sphinx配置文件
3、生成索引
4、启动Searchd服务进程,并开放端口9312
5、用PHP客户端程序去连接Sphinx服务
三:sphinx配置
1:配置:
sphinx最麻烦的就是文件配置,打开/usr/local/sphinx-3.0.3/etc/sphinx.conf配置文件,这个文件有一大堆。
整理一下,其实一共有7个模块:
#主数据源
source src1{
}
#增量数据源
source src1throttled : src1{
}
#主数据索引
index test1{
}
#增量数据索引
index test1stemmed : test1{
}
#分布式索引
index dist1{
}
#索引器
indexer{
}
#服务进程
searchd{
}现在用一个数据库做实验,数据库名称:abc,表:news,news表里有三个字段:id,title,content;表中添加一些数据。etc里面还有一个sphinx-min.conf.dist,最小配置,我们先按照这个来改。
#
# Minimal Sphinx configuration sample (clean, simple, functional)
#
#主数据源配置
source main #默认是src1,我们取一个名字:main
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass = 123
sql_db = abc
sql_port = 3306 # optional, default is 3306
sql_query = \
SELECT id,title,content \
FROM news #获取数据的sql语句
sql_field_string = title
sql_field_string = content #设置这两个字段参与全文搜索
#sql_query_pre = SET SESSION query_cache_type=OFF #关闭查询缓存,如果mysql开启了缓存,则这里开启这一行,否则注释掉,不然会报错
}
#主数据索引配置
index test1
{
source = main #索引源声明,我们主数据源配置为main
path = /var/data/test1 #索引表放在这里,其他地方也可以,名字也叫test1,data如果不存在就先建立
ngram_len= 1 #简单分词,搜索中文必须设置1
ngram_chars= U+3000..U+2FA1F #需要分词的字符,搜索中文时必须
}
indexer
{
mem_limit = 128M
}
searchd
{
listen = 9312
listen = 9306:mysql41
log = /var/log/searchd.log
query_log = /var/log/query.log
read_timeout = 5
max_children = 30
pid_file = /var/log/searchd.pid
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
workers = threads # for RT to work
binlog_path = /var/data
}
其他的配置先不动,实时索引,增量都先删掉,先看看效果!
2:创建索引:
/usr/local/sphinx-3.0.3/bin/indexer -c /usr/local/sphinx-3.0.3/etc/sphinx.conf --all
 报错,提示没有mysql客户端。
报错,提示没有mysql客户端。
搜索一下:
 有啊,
有啊,
执行一下软连接吧:注意机器位数
ln -s /usr/lib64/mysql/libmysqlclient.so.20.3.4 /usr/lib/libmysqlclient.so #32位机器 ln -s /usr/lib64/mysql/libmysqlclient.so.20.3.4 /usr/lib64/libmysqlclient.so #64位机器
再次执行:
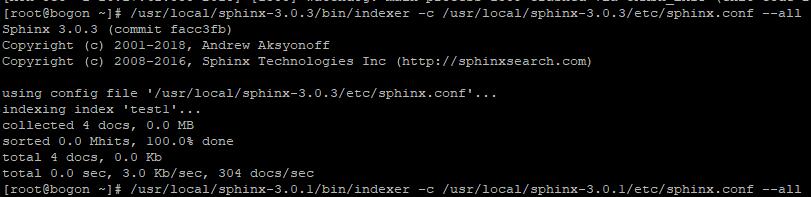 OK,生成了4条索引,这里数据库我加了4条数据。
OK,生成了4条索引,这里数据库我加了4条数据。
生产索引之后启动sphinx,启动后PHP才能调用:
/usr/local/sphinx-3.0.3/bin/searchd -c /usr/local/sphinx-3.0.3/etc/sphinx.conf
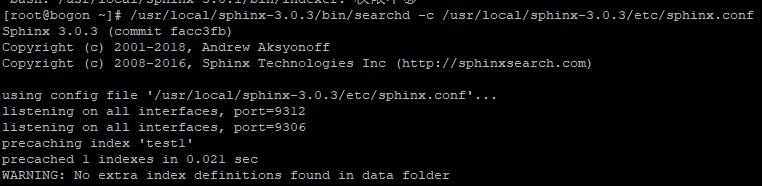
启动成功画面
新版本的sphinx已经取消了seach命令,没法通过内置函数测试,只能通过API,下面安装支持PHP
四:安装libsphinxclient(PHP调用需要用到这个模块)
cd /usr/local/sphinx-3.0.3/api/libsphinxclient ./configure --prefix=/usr/local/sphinxclient make make install
五:安装PHP sphinx扩展
pecl上没有php7的扩展,下载地址:
http://git.php.net/?p=pecl/search_engine/sphinx.git;a=shortlog;h=refs/heads/php7
./configure --with-php-config=/usr/local/php/bin/php-config --with-sphinx make make install
我这里make不成功,一堆报错,PHP7.2,先不管了,先用sphinx api调用。PHP调用sphinx有两种方式:一种是通过pecl扩展,另外一种就是通过API。
六:通过API调用:
把sphinx目录下的api目录下的sphinxapi.php文件复制一份出来:
<?php
header('Content-Type:text/html;charset=utf-8');
require('sphinxapi.php');
$sphinx = new SphinxClient();
$sphinx->SetServer('192.168.17.160',9312);
$res = $sphinx->Query("lijie","*");
print_r($res);
if ( !$res )
{
die ( "ERROR: " . $sphinx->GetLastError() . ".\n" );
} 
新加一条记录:INSERT INTO `news` (`title`, `content`) VALUES('china', 'china chinese');
查找china,发现啥都没有?怎么回事?因为新添加了记录,所以要重新更新索引,有两种方式,一种是增量更新,一种是全部更新,虽然sphinx全部更新很快,但也还是推荐增量更新,没必要重复工作。
这里先试一下全部更新,运行:
/usr/local/sphinx-3.0.3/bin/indexer -c /usr/local/sphinx-3.0.3/etc/sphinx.conf --all --rotate # --rotate:通俗的说就是:在sphinx运行的时候,需要更新索引就带上这个参数,干脆叫热更新吧,否则需要重启searchd # --all :全部索引,也可以单独制定索引,比如我们这里是:test1 --rotate
 数据找到了,id为:5
数据找到了,id为:5
七:增量索引
所谓增量索引,就是mysql数据有改动,那么sphinx也只改动mysql改动的部分,不需要全部更新,是不是很科学?试下怎么配置。
思路:mysql表中建立一个计数器表,更新主索引的时候,把数据源中最大的ID值写入计数器,做索引只更新小于等于该值的记录,增量索引更新大于该值的记录
步骤:
1:新建一个计数器表
CREATE TABLE sph_counter(counter_id INTEGER PRIMARY KEY NOT NULL,max_doc_id INTEGER NOT NULL);2:运行sql语句,把当前sphinx用到的mysql表中最大的id值插入进去,这里是news表
replace into sph_counter select 1,max(id) from news3:修改sphinx配置文件
#
# Minimal Sphinx configuration sample (clean, simple, functional)
#
#主数据源配置
source main
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass = 123
sql_db = abc
sql_port = 3306 # optional, default is 3306
sql_query_pre = SET NAMES utf8
#把news表中id的最大值插入到sph_counter表里,这就实现了计数器更新
sql_query_pre = replace into sph_counter select 1,max(id) from news
#主数据源的数据取之于计数表中最大值以前的数据,因为最大值以后的数据在增量数据源中取
sql_query = \
SELECT id,title,content \
FROM news WHERE id<=(SELECT max_doc_id FROM sph_counter WHERE counter_id=1);
sql_field_string = title
sql_field_string = content #设置这两个字段参与全文搜索
#sql_attr_uint = group_id
#sql_attr_timestamp = date_added
}
#增量数据源
source delta : main #delta是增量数据源名字,main是主数据,delta继承main
{
sql_query_pre = SET NAMES utf8
sql_query = SELECT id,title,content \
FROM news WHERE id>(SELECT max_doc_id FROM sph_counter WHERE counter_id=1);
}
#主索引配置
index test1
{
source = main
path = /var/data/test1 #主数据索引位置
ngram_len= 1 #简单分词,搜索中文必须设置1
ngram_chars= U+3000..U+2FA1F #需要分词的字符,搜索中文时必须
}
#增量索引
index delta : delta { #delta是增量索引名字 增量数据源
source = delta #继承增量索引源
path = /var/data/delta #增量索引位置
ngram_len= 1 #简单分词,搜索中文必须设置1
ngram_chars= U+3000..U+2FA1F #需要分词的字符,搜索中文时必须
}
indexer
{
mem_limit = 128M
}
searchd
{
listen = 9312
listen = 9306:mysql41
log = /var/log/searchd.log
query_log = /var/log/query.log
read_timeout = 5
max_children = 30
pid_file = /var/log/searchd.pid
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
workers = threads # for RT to work
binlog_path = /var/data/#关闭binlog日志
}
运行一下:#单独更新delta,delta是我们的增量索引 /usr/local/sphinx-3.0.3/bin/indexer -c /usr/local/sphinx-3.0.3/etc/sphinx.conf delta --rotate
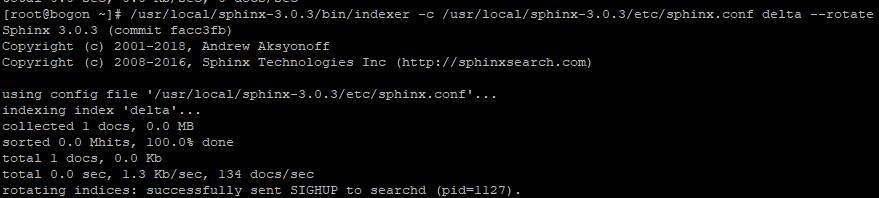 更新成功
更新成功
添加一条数据,更新一下增量数据源,PHP查看一下:
//单独查询delta索引,查询所有索引用 *
$res = $sphinx->Query("fefds","delta");
print_r($res); 可以看到,数据成功检索
可以看到,数据成功检索4:索引合并:
添加了增量索引,这里就出现了两个索引源,比如这里是test1和delta;有两种方式解决这个问题。
(1):索引合并
indexer --merge test1 delta --rotate #将delta合并到test1中(2):客户端调用解决
索引不合并,通过客户端调用解决。两个索引合并时,都要读入,然后还要写一次硬盘,IO操作量很大。而在php API调用时,Query($query,$index)中$index可以设置多个索引名,如Query($query,"test1;delta"),也就没有必要一定将两个索引合并。
5:合并过滤(参考以下图片,该图片来自于互联网)

6:定时执行:
我们弄一个定时脚本:主索引,一天更新一次即可,可以选择在深夜人少的时候干这个事情,增量索引5分钟更新一次。具体时间根据业务需求调整完善。
八:分布式索引
分布式是为了改善查询延迟问题和提高多服务器、多CPU 或多核环境下的吞吐率,对于大量数据(即十亿级的记录数和TB级的文本量)上的搜索应用来说是很关键的。
分布式思想:对数据进行水平分区(HP,Horizontally partition),然后并行处理,当searched收到一个对分布式索引的查询时,它做如下操作
1.连接到远程代理
2.执行查询
3.对本地索引进行查询
4.接收来自远程代理的搜索结果
5.将所有结果合并,删除重复项(这里就要用到第七节的4,5)
6.将合并后的结果返回给客户端
配置很简单:
index dist
{
type=distributed #表示分布式索引
local=chunk1 #本地索引chunk1
agent=localhost:9312:chunk2 本地
agent=192.168.100.2:9312:chunk3 远程
agent=192.168.100.2:9312:chunk4 远程
}九:中文分词
sphinx提供了简单的中文分词,但精确度不高,实际使用意义不大,本来Coreseek很不错,Coreseek是基于sphinx的,说白了其实就是支持中文的sphinx,不过Coreseek网站N久打不开了,换来换去经常不稳定,这里我们试试另外一个开源分词系统——scws
官方地址:http://www.xunsearch.com/scws/
大概看了下,还不错,居然支持PHP7,业界良心啊。
1:安装scws
wget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2 tar -xvf scws-1.2.3.tar.bz2 cd scws-1.2.3/ ./configure --prefix=/usr/local/scws make make install
2:安装scws php扩展
扩展在上一步解压的scws文件夹的phpext文件下
cd phpext/ /usr/local/php/bin/phpize ./configure --with-php-config=/usr/local/php/bin/php-config --with-scws=/usr/local/scws/ make make install
把scws.so添加到php配置文件中去,php.ini设置:
[scws] extension = scws.so scws.default.charset = utf-8 scws.default.fpath = /usr/local/scws/etc

3:安装scws词库
wget http://www.xunsearch.com/scws/down/scws-dict-chs-utf8.tar.bz2 tar -xvf scws-dict-chs-utf8.tar.bz2 #解压出来是:dict.utf8.xdb 文件 #把这个文件移到/usr/local/scws/etc中 cp dict.utf8.xdb /usr/local/scws/etc4:测试
<?php
header('Content-Type:text/html;charset=utf-8');
$key = "你好";
//========================================scws分词
$so = scws_new();
$so->set_charset('utf-8');
//默认词库
$so->add_dict(ini_get('scws.default.fpath') . '/dict.utf8.xdb');
//自定义词库
// $so->add_dict('./dd.txt',SCWS_XDICT_TXT);
//默认规则
$so->set_rule(ini_get('scws.default.fpath') . '/rules.utf8.ini');
//设定分词返回结果时是否去除一些特殊的标点符号
$so->set_ignore(true);
//设定分词返回结果时是否复式分割,如“中国人”返回“中国+人+中国人”三个词。
// 按位异或的 1 | 2 | 4 | 8 分别表示: 短词 | 二元 | 主要单字 | 所有单字
//1,2,4,8 分别对应常量 SCWS_MULTI_SHORT SCWS_MULTI_DUALITY SCWS_MULTI_ZMAIN SCWS_MULTI_ZALL
$so->set_multi(false);
//设定是否将闲散文字自动以二字分词法聚合
$so->set_duality(false);
//设定搜索词
$so->send_text($key);
$words_array = $so->get_result();
$words = "";
foreach($words_array as $v)
{
$words = $words.'|('.$v['word'].')';
}
//加入全词
#$words = '('.$key.')'.$words;
$words = trim($words,'|');
$so->close();
echo '<p>输入:'.$key.'</p>'."\r\n";
echo '<p>分词:'.$words.'</p>'."\r\n";
//========================================sphinx搜索
require('sphinxapi.php');
$sphinx = new SphinxClient();
$sphinx->SetServer('192.168.17.160',9312);
$res = $sphinx->Query($words,"*");
print_r($res);
if ( !$res )
{
die ( "ERROR: " . $sphinx->GetLastError() . ".\n" );
} 