一致性哈希算法在分布式中的运用
一:普通哈希算法
1:普通哈希算法,一般在应用中为哈希取模法。假设有3台cache,缓存通过key哈希取模,存放在不同的cache上。这里的算法为:
key%3。为什么要哈希,取模肯定要数字才能计算,key不一定是数字。
2:所以正确的PHP算法为:
//crc32返回的结果在32位机上会产生溢出,结果可能为负数。在64位机上不会溢出,总是正值,所以这里用sprintf转一下
sprintf('%u', crc32($key))%3
3:看起来好像没什么问题,但是如果要踢掉一台cache,或者增加一台cache的话,那么数据就乱了。这里为了简单明了,我们用数字做一下演示,3台服务器:
//运用取模法
for($i=0;$i<=9;$i++){
echo $i.'--'.fmod((float)$i,3 ).'号服务器'.'
';
} 从这结果可以看到:
从这结果可以看到:0号服务器有:0;3;6;9
1号服务器有:1;4;7
2号服务器有:2;5;8
随着业务量上升,3台服务器不够用了,现在加1台,4台服务器。
//运用取模法
for($i=0;$i<=9;$i++){
echo $i.'--'.fmod((float)$i,4 ).'号服务器'.'
';
} 再看下这个结果:
再看下这个结果:0号服务器有:0;4;8
1号服务器有:1;5;9
2号服务器有:2;6;8
3号服务器有:3;7两个对比一下,其结果几乎完全变了,这会造成什么后果?这样会造成大部分缓存都无法命中。这也是哈希取模不适合mysql自动分表的原因,缓存服务器还稍微好一点,结果不存在就从数据库提起,但如果是弄mysql自动分表,就找不到数据了。除非分表的数量是固定的,不然加表很蛋痛。
二:一致性哈希算法
1:一致性哈希就是为了解决上述问题。
2:基本模型:
一致性哈希算法是对2^32取模,首先把一个圆看成是二的三十二次方个点组成,这个圆环就称为Hash环,服务器节点部署在圆点上,数据根据顺时针找到最近的节点,然后部署在该节点上。
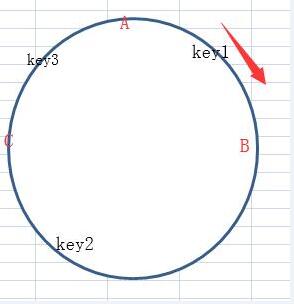 这个哈希圆上有三台服务器,A,B,C,key为数据,根据顺时针找最近的节点。那么上图为:key1在B节点上,key2在C节点上。key3在A服务器。
这个哈希圆上有三台服务器,A,B,C,key为数据,根据顺时针找最近的节点。那么上图为:key1在B节点上,key2在C节点上。key3在A服务器。
随着业务的发展,现在节点不够了,要增加一台服务器。
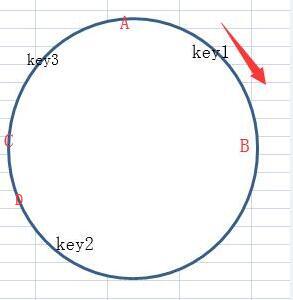 现在增加了一台D服务器,根据顺时针,找最近的节点,可以看到key2以前保存在C节点的服务器,现在保存在D服务器上,也就是说只要迁移C服务器的数据就行了,不需要所有服务器都迁移,这就大大减少了服务器迁移时间和难度。
现在增加了一台D服务器,根据顺时针,找最近的节点,可以看到key2以前保存在C节点的服务器,现在保存在D服务器上,也就是说只要迁移C服务器的数据就行了,不需要所有服务器都迁移,这就大大减少了服务器迁移时间和难度。
不过上面还是有个问题,数据不均衡怎么办?上面两个图,数据是相对均衡的,但数据也可能是这样:
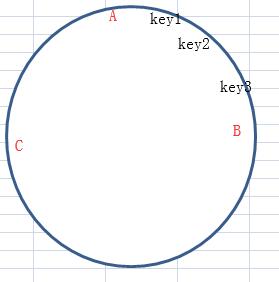 这样key1,key2,key3都保存在了B服务器,这出现了明显的便宜,怎么解决这个问题?这里就需要引入虚拟节点的概念。
这样key1,key2,key3都保存在了B服务器,这出现了明显的便宜,怎么解决这个问题?这里就需要引入虚拟节点的概念。
虚拟节点:基于原有的节点映射出N个子节点
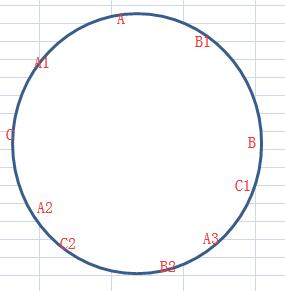 映射虚拟节点,尽可能的让数据均匀分布。"虚拟节点"是"实际节点"在hash环上的复制品,一个实际节点可以对应多个虚拟节点。增加虚拟节点,平均分布的可能性就增加了。虚拟节点数越多,分布越均匀,但程序的分布式运算越慢!
映射虚拟节点,尽可能的让数据均匀分布。"虚拟节点"是"实际节点"在hash环上的复制品,一个实际节点可以对应多个虚拟节点。增加虚拟节点,平均分布的可能性就增加了。虚拟节点数越多,分布越均匀,但程序的分布式运算越慢!
未完待续!
