Mysql使用技巧以及sql优化
一:使用技巧
1:正则函数:regexp
select * from t1 where name regexp '^abc' #匹配以abc开头的数据 select * from t1 where name regexp 'abc$' #匹配以abc结尾的数据
更多规则参考手册,PEGEXP可以代替LIKE,但是性能不如like,应尽量避免使用,网上说比like性能高的都是扯淡。
2:字符串替换:replace
a:替换表中的数据
#把id等于9的字段name中的值:abc,替换成:12345 update t1 set name = replace(name,'abc','12345') where id = 9b:查询替换数据
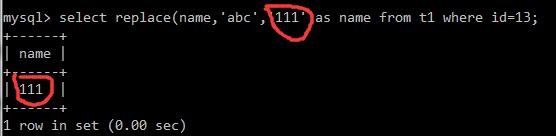
select replact(name,'abc','111') as name from t1 where id=13;如果满足条件,这里查询出来的就是111,这种是查询出了后替换,不会改变数据库里的值
获取0到9之间的一个数,利用这个函数和order by能够把数据随机排序
select * from t1 order by rand() #随机提取数据 select * from t1 order by rand() #limit 5 #随机提取5条数据比如需要抽样检查数据的时候,用这个很方便
4:with rollup关键字
with rollup可以统计更多的信息,但不能和order by结合使用
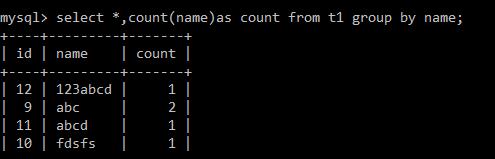
普通的聚合:
加with rollup之后
select *,count(name) as count from t1 group by name with rollup;
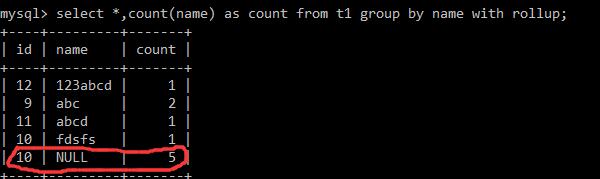
这里统计出了一共聚合了多少次。
二:优化
1:通过show status 了解sql执行频率
格式:mysql> show [session|global]status
备注:session(默认)表示当前连接;global:表示数据库启动至今
show status; show global status; show session status like 'Com_%' show global sataus status 'Com_%'一般关注增删查改:
(1):你登录mysql到现在有多少次增删查改
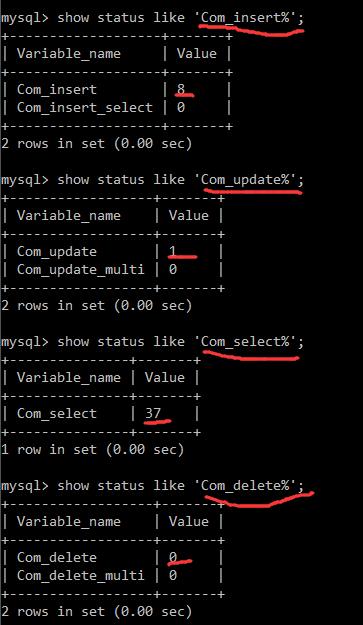
因为默认就是session,所以不用加session:show session status like 'Com_%'
(2):mysql启动至今有多少次增删查改
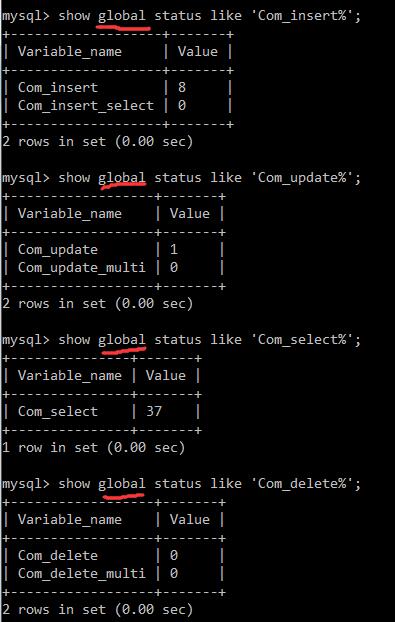
加 global 参数就是查询启动至今的记录。
注意:
a:这个命令是查看当前数据库,不是查看所有数据库,先确定你在哪个数据库?比如查看 add数据库,先use add;
b:通过该命令能够很直观的知道您的数据库是读取多,还是写入多,从而为数据库优化提供参考

通过此图可以看到,Com_可以查询所有的表,也可以通过InnoDB_rows只查看InnoDB表;但是有一个不同点,Com_查看的是次数,InnoDB_rows查看的是影响的行数,比如执行一次可能会影响很多行。比如执行select limit 10;在Com_只算一次,但在InnoDB_rows中就是10次,影响了10行。
2:查看慢查询
show variables like "%slow%"
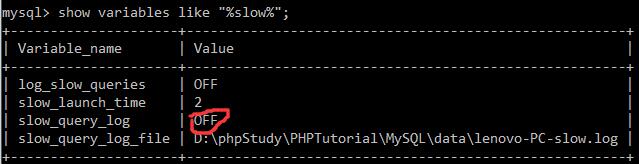
显示慢查询是关闭的。
show variables like "%long%"
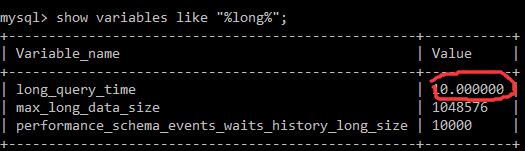
可以通过修改mysql配置文件启动慢查询
[mysqld] slow_query_log = ON long_query_time = 2 #超过2秒的sql保存慢日志 log-slow-queries = /tmp/mysql-slow.log #慢日志语句修改配置文件后重启服务器,通过慢查询可以知道哪些SQL耗费时间。
3:定位执行效率低的SQL(desc或者explain)
desc select * from t1 explain select * from t1
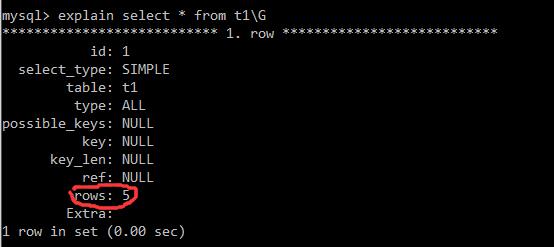
这里影响了5行;key:NULL,显示没用到索引,更多参数见下图。

4:sql语句优化
(1):count(*) 和count(字段)
count(*)是统计包含null的记录,而count(字段)不含null;
count(*)在MyISAM中,如果没有where条件,速度非常快,不用扫描表,直接获取这个值
count(*)在InnoDB中,会根据mysql优化器使用某个字段索引,不一定是主键。
(2):避免在列上运算,因为这样索引不起作用,而且增加运算开销
select * from t1 where YEAR(d) >= 2018; #不建议 select * from t where d >='2018' #最佳用法
(3):select * from t1 where id=1 or id=2;改成select * from t1 where in(1,2);
(4):or在有的情况下不会走索引,比如 id =1 or name=2,如果name没有索引,那么整个语句不会用到索引。具体可以通过explain 检测
(5):插入多条数据
insert into t1(name) values('zhansan'),('lisi'),('waner')(6):少用left join语句
(7):关闭group by排序:
select * from t1 group by sex; select * from t1 group by sex order by null; # order by null关闭proup排序
(8):少用嵌套查询
#这里嵌套查询,外面t1不会用到索引 select * from t1 where id in(select uid from t2) #改成 select t1.* from t1,t2 where t1.id=t2.uid;
5:索引优化
索引一般是考虑在sql语句的order by、group by 、where 、having使用索引
6:表检测
(1):检查表是否有错误?
check table t1;#检查t1表
(2):优化表
optimize table t1; #优化t1表

